AnandTech Article Channel |

- Calxeda's ARM server tested
- Inside AnandTech 2013: All-SSD Architecture
- Inside AnandTech 2013: The Hardware
- Imagination Technologies Confirms PowerVR SGX 544 IP used in Exynos 5 Octa
| Posted: 12 Mar 2013 04:14 PM PDT ARM based servers hold the promise of extremely low power and excellent performance per Watt ratios. It's possible to place an incredible amount of servers into a single rack—there are already implementations with as many as 1000 ARM servers in one rack (48 server nodes in a 2U chassis). And all of those nodes consume less than 5KW (or around 5W per quad-core ARM node). But whenever a new technology is hyped, it is good to remain skeptical. The media hypes and raves about new trends because people love to read about something new, but at the end of the day, the system administrator has to keep his IT services working and convince his boss to invest in new technologies. Hundreds of opinion pages have been and will be written about the ARM vs. x86 server war, but nothing can beat a test run with real world benchmarks, and that is what we'll look at today. We have put some heavy loads on our Boston Viridis cluster system running 24 web sites—among other applications—and measured throughput, response times, and power. We'll be comparing it with the lower power Xeons to see how the current ARM servers compare to the best Intel Xeon offerings. Performance per Watt, Performance per dollar, whatever your metric is, we have the hard numbers. | ||||||||||||||||||||||
| Inside AnandTech 2013: All-SSD Architecture Posted: 12 Mar 2013 08:28 AM PDT
When it comes to server hardware failures, I've seen them all with our own infrastructure. With the exception of CPUs, I've seen virtually every other component that could fail, fail in the past 16 years of running AnandTech. Motherboards, power supplies, memory and of course, hard drives. By far the most frequent failure in our infrastructure had to be mechanical drives. Within the first year after the launch of Intel's X25-M in 2008, I had transitioned all of my testbeds to solid state drives. The combination of performance and reliability was what I needed. Most of my testbeds were CPU bound, so I didn't necessarily need a ton of IO performance - but having the headroom offered by a good SSD meant that I could get more consistent CPU performance results between runs. The reliability side was simple to understand - with a good SSD, I wouldn't have to worry about my drive dying unexpectedly. Living in fear of a testbed hard drive dying over the weekend before a big launch was a thing of the past. When it came to rearchitecting the AnandTech server farm, these very same reasons for going the SSD route on all of our testbeds (and personal systems) were just as applicable to the servers that ran AnandTech. Our infrastructure is split up between front end application servers and back end database servers. With the exception of the boxes that serve our images, most of our front end app servers don't really stress IO all that much. The three 12-core virtualized servers at the front end would normally be fine with some hard drives, however we instead decided to go with mainstream SSDs to lower the risk of a random mechanical failure. We didn't need the endurance of an enterprise drive in these machines since they weren't being written to all that frequently, but we needed reliable drives. Although quite old by today's standards, we settled on 160GB Intel X25-M G2s but partitioned the drives down to 120GB in order to ensure they'd have a very long lifespan. Where performance matters more is in our back end database servers. We run a combination of MS SQL and MySQL, and our DB workloads are particularly IO intensive. In the old environment we had around a dozen mechanical drives in various RAID configurations powering all of the databases that ran the site. To put performance in perspective, I grabbed our old Forum Database server and took a look at the external SAS RAID array we had created. Until last year, the Forums were powered by a combination of 6 x Seagate Barracuda ES.2s and 4 x Seagate Cheetah 10K.7s. For the new Forums DB we moved to 6 x 64GB Intel X25-Es. Again, old by modern standards, but a huge leap above what we had before. To put the performance gains in perspective I ran some of our enterprise IO benchmarks on the old array and the new array to compare. We split the DB workload across the Barracuda ES.2 array (6 drive RAID-10) and the Cheetah array (4 drive RAID-5), however to keep things simple I just created a 4-drive RAID-0 using the Cheetahs which should give us more than a good indication of peak performance of the old hardware:
The two SQL tests are actually from our own environment, so the performance gains are quite applicable. The advantage here is only around 2.7x. In reality the gains can be even greater, but we don't have good traces of our live DB load - just some of our most IO intensive tasks on the DB servers. The final benchmark however does give us some indication of what a more random enterprise workload can enjoy with a move to SSDs from a hard drive array. Here the performance of our new array is nearly 20x the old HDD array. Note that there's another simplification that comes along with our move to SSDs: we rely completely on Intel's software RAID. There are no third party RAID controllers, no extra firmware/drivers to manage and validate, and there's no external chassis needed to get more spindles. We went from a 4U HP DL585 server with a 2U Promise Vtrak J310s chassis and 10 hard drives, down to a 2U server with 6 SSDs - and came out ahead in the performance department. Later this week I'll talk about power savings, which ended up being a much bigger deal. This is just the tip of the iceberg. In our specific configuration we went from old hard drives to old SSDs. With even greater demands you could easily go to truly modern enterprise SSDs or even PCIe based solutions. Using a combination of consumer and enterprise drives isn't a bad idea if you want to transition to an all-SSD architecture. Deploying reliable consumer drives in place of lightly used hard drives is a way to cut down the number of moving parts in your network, while moving to higher performing/higher endurance enterprise SSDs can deliver significant performance benefits as well. | ||||||||||||||||||||||
| Inside AnandTech 2013: The Hardware Posted: 12 Mar 2013 06:40 AM PDT
By the end of 2010 we realized two things. First, the server infrastructure that powered AnandTech was getting very old and we were seeing an increase in component failures, leading to higher than desired downtime. Secondly, our growth over the previous years had begun to tax our existing hardware. We needed an upgrade. Ever since we started managing our own infrastructure back in the late 90s, the bulk of our hardware has always been provided by our sponsors in exchange for exposure on the site. It also gives them a public case study, which isn't always possible depending on who you're selling to. We always determine what parts we go after and the rules of engagement are simple: if there's a failure, it's a public one. The latter stipulation tends to worry some, and we'll get to that in one of the other posts. These days there's an tempting alternative: deploying our infrastructure in the cloud. With low (to us) hardware costs however, doing it internally still makes more sense. Furthermore, it also allows us to do things like do performance analysis and create enterprise level benchmarks using our own environment. Spinning up new cloud instances at Amazon did have it appeal though. We needed to embrace virtualization and the ease of deployment benefits that came with it. The days of one box per application were over, and we had more than enough hardware to begin to consolidate multiple services per box. We actually moved to our new hardware and software infrastructure last year. With everything going on last year, I never got the chance to actually talk about what our network ended up looking like. With the debut of our redesign, I had another chance to do just that. What will follow are some quick posts looking at storage, CPU and power characteristics of our new environment compared to our old one. To put things in perspective. The last major hardware upgrade we did at AnandTech was back in the 2006 - 2007 timeframe. Our Forums database server had 16 AMD Opteron cores inside, it's just that we needed 8 dual-core CPUs to get there. The world changed over the past several years, and our new environment is much higher performing, more power efficient and definitely more reliable. In this post I want to go over, at a high level, the hardware behind the current phase of our infrastructure deployment. In the subsequent posts (including another one that went live today) I'll offer some performance and power comparisons, as well as some insight into why we picked each component. I'd also like to take this opportunity to thank Ionity, the host of our infrastructure for the past 12 months. We've been through a number of hosts over the years, and Ionity marks the best yet. Performance is typically pretty easy to guarantee when it comes to any hosting provider at a decent datacenter, but it's really service, response time and competence of response that become the differentiating factors for us. Ionity delivered on all fronts, which is why we're there and plan on continuing to be so for years to come. Out with the OldOur old infrastructure featured more than 20 servers, a combination of 1U dual-core application servers and some large 4U - 5U database servers. We had to rely on external storage devices in order to give us the number of spindles we needed in order to deliver the performance our workload demanded. Oh how times have changed. For the new infrastructure we settled on a total of 12 boxes, 6 of which are deployed now and another 6 that we'll likely deploy over the next year for geographic diversity as well as to offer additional capacity. That alone gives you an idea of the increase in compute density that we have today vs. 6 years ago: what once required 20 servers and more than a single rack can easily be done in 6 servers and half a rack (at lower power consumption too). Of the six, a single box currently acts as a spare - the remaining five are divided as follows: two are on database duty, while the remaining three act as our application servers. Since we were bringing our own hardware, we needed relatively barebones server solutions. We settled on Intel's SR2625, a fairly standard 2U rackmount with support for the Intel Xeon L5640 CPUs (32nm Westmere Xeons) we would be using. Each box is home to two of these processors, each of which features 6-cores and a 12MB L3 cache. Each database server features 48GB of Kingston DDR3-1333 while the application servers use 36GB each. At the time that we speced out our consolidation plans, we didn't need a ton of memory but going forward it's likely something we'll have to address. When it comes to storage, the decision was made early on to go all solid-state. The problem we ran into there is most SSD makers at the time didn't want to risk a public failure of their SSDs in our environment. Our first choice declined to participate at the time due to our requirement of making any serious component failures public. Things are different today as the overall quality of all SSDs has improved tremendously, but back then we were left with one option: Intel. Our application servers use 160GB Intel X25-M G2s, while our database servers use 64GB Intel X25-Es. The world has since moved to enterprise grade MLC in favor of SLC NAND, but at the time the X25-Es were our best bet to guarantee write endurance for our database servers. As I later discovered, using heavily overprovisioned X25-M G2s would've been fine for a few years, but even I wanted to be more cautious back then. The application servers each use 6 x X25-M G2s, while the database servers use 6 x X25-Es. To keep the environment simple, I opted against using any external RAID controllers - everything here is driven by the on-board Intel SATA controllers. We need multiple SSDs not for performance reasons but rather to get the capacities we need. Given that we migrated from a many-drive HDD array, the fact that we only need a couple of SSDs worth of performance per box isn't too surprising. Storage capacity is our biggest constraint today. We actually had to move our image hosting needs to our Ionity's cloud environment due to our current capacity constraints. NAND lithographies have shrunk dramatically since the days of the X25-Es and X25-Ms, so we'll likely move image hosting back on to a few very large capacity drives this year. That's the high level overview of what we're running on, I also posted some performance data for the improvement we saw in going to SSDs in our environment here.
Gallery: Inside AnandTech 2013: The Hardware       | ||||||||||||||||||||||
| Imagination Technologies Confirms PowerVR SGX 544 IP used in Exynos 5 Octa Posted: 12 Mar 2013 06:20 AM PDT
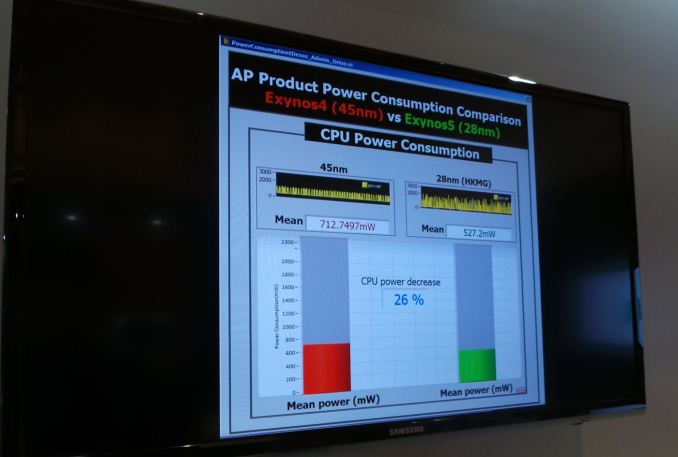
ARM was being unusually coy when talking about the GPU IP used in Samsung's recently announced Exynos 5 Octa. We eventually found out why: unlike the Exynos 5 Dual and Exynos 4 silicon, ARM's Mali GPU isn't included in the Exynos 5 Octa's floorplan. Through a bit of digging we concluded that Samsung settled on a PowerVR SGX 544MP3 GPU. We couldn't disclose how we came to this conclusion publicly, but thankfully today Imagination Technologies confirmed the use of their IP in the Exynos 5 Octa 5410. All Imagination confirmed was the use of PowerVR SGX 544 IP in Exynos 5 Octa, however we still believe that Samsung used three cores running at up to 533MHz. Thankfully we should be able to confirm a lot of this very soon. The Exynos 5 Octa is widely expected to be used in the international variants of Samsung's upcoming Galaxy S 4. We will be at Samsung's Galaxy S 4 unpacked launch event in NYC this Thursday to find out. | ||||||||||||||||||||||












| You are subscribed to email updates from AnandTech To stop receiving these emails, you may unsubscribe now. | Email delivery powered by Google |
| Google Inc., 20 West Kinzie, Chicago IL USA 60610 | |



No comments:
Post a Comment